A Viable Alternative to Machine Learning Algorithms-Subspace Identification of Dynamical Systems and Time Series
For a relatively broad class of problems, subspace identification algorithms perform exceptionally well and outperform most of the algorithms including neural networks for estimation of linear systems.
Also, I (Aleksandar Haber) am not the person who developed this amazing method that unfortunately is not widely known (in the machine learning community). There is a long line of talented researchers who worked on the development of the method.
For impatient, the code can be found here, on my GitHub page
In this post, we provide a detailed explanation of a Subspace Identification (SI) algorithm that can be used to estimate a state-space model of a dynamical systems by performing a few relatively simple numerical steps.
The main advantage of the SI algorithm is that does not rely upon iterative optimization method, and its main numerical steps are relying upon the least-squares method and on the singular value decomposition. In our opinion, SI
algorithms are a viable alternative to machine learning approaches for estimating models of dynamical systems. We start our discussion with the explanation of the class of models we are trying to estimate.
where is the discrete time instant, is the system state, is the state order, is the control input, is
the observed output, is the process disturbance, is the measurement noise, , , and are the system matrices.
The vectors and are usually known or only their statistics are known. For the purpose of identifying the system model, under some assumptions on the statistics of the vectors and ,
to the system \eqref{eq1:stateDiscrete}-\eqref{eq1:outputDiscrete} we can associate another state-space model having the following form
where and . The state-space model \eqref{eq1:stateDiscreteKalman}-\eqref{eq1:outputDiscreteKalman} is often referred to as the Kalman innovation state-space model. The vector and the matrix model the effect of the process disturbance and the measurement noise on the system dynamics and the system output. The identification problem can be formulated as follows.
From the set of input-output data estimate the model order and the system matrices and of the state-space model \eqref{eq1:stateDiscreteKalman}-\eqref{eq1:outputDiscreteKalman}.
It should be emphasized that once the matrices , and are estimated, we can disregard the matrix if we want to work with the model \eqref{eq1:stateDiscrete}-\eqref{eq1:outputDiscrete}.
Before we start with the explanation of the SI algorithm, we first introduce a model and its simulation code that we use for testing.
Test Model - System of Two Objects Connected by Springs and Dampers
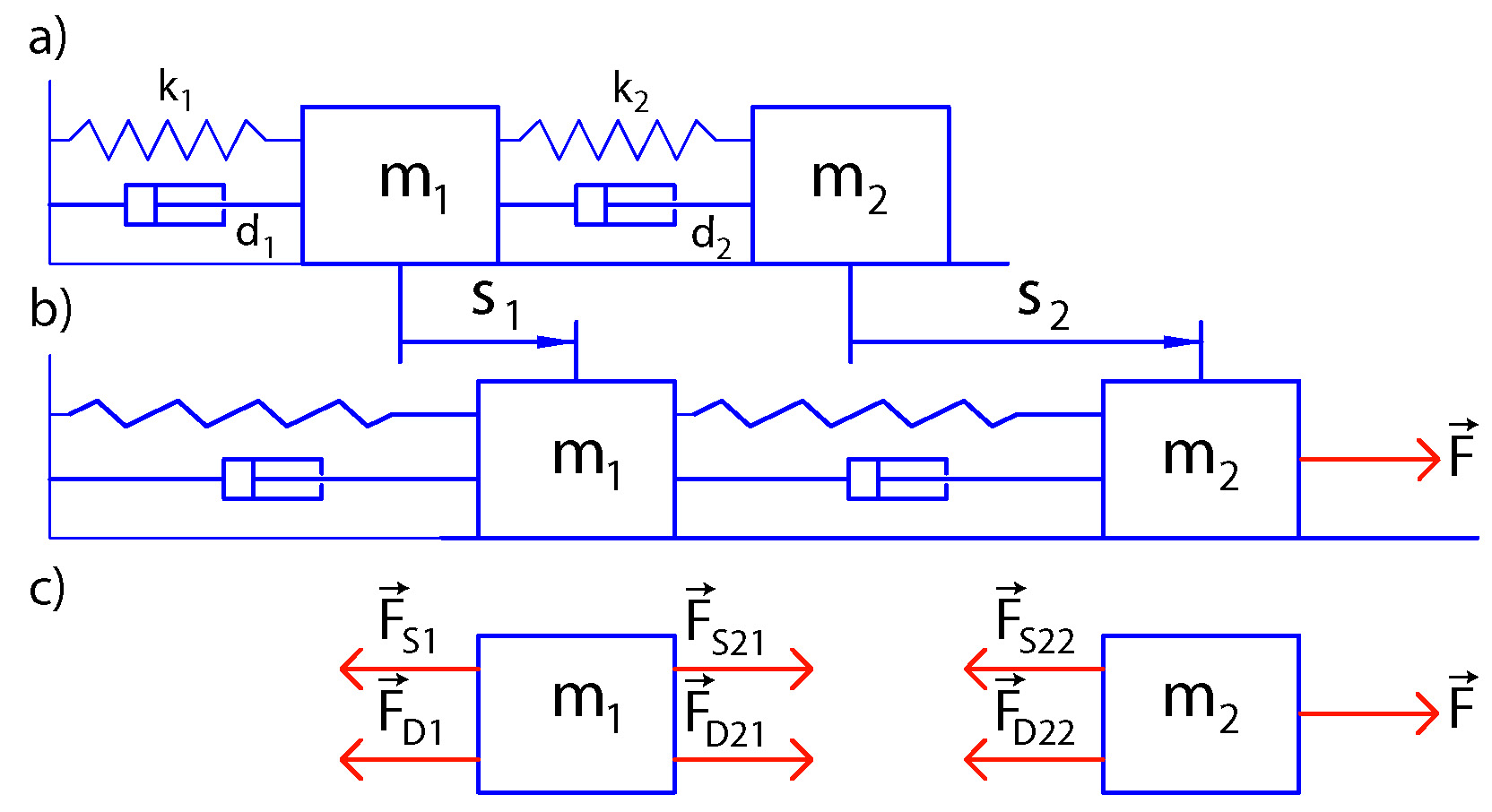
The sketch of the system is shown in Fig.1(a) below. The system consists of two objects of the masses and connected by a spring and a damper. In addition, the object 1 is attached to the wall by a spring and a damper. Figure 2(b) shows the situation when the force is acting on the second body. The displacements of the objects and are denoted by and .
 |
|---|
| Figure 1: (a) The system composed of two objects connected by a spring and a damper. (b) Object displacements when the force is acting on the second body. (c) Free body diagrams of the system. |
Figure 1(c) shows free body diagrams of the system. The force is the force that the spring 1 is exerting on the body 1. The magnitude of this force is given by , where is the spring constant. The force is the force that the damper 1 is exerting on the body 1. The magnitude of this force is given by , where is the damper constant and is the first derivative of the displacement (velocity of the body 1). The force is the force that the spring 2 is exerting on the body 1. The magnitude of this force is given by , where is the spring constant. The force is the force that the damper 2 is exerting on the body 1. The magnitude of this force is given by , where is the damper constant. The force is the force that the spring 2 is exerting on the body 2. The force is the force that the damper 2 is exerting on the body 2. We assume that the masses of springs and dampers are much smaller than the masses of the objects and consequently, they can be neglected. Consequently, we have and .
The next step is to apply the Newton second law:
Then, we introduce the state-space variables
By substituting the force expressions in \eqref{sNl1}-\eqref{sNl2} and by using \eqref{stateSpaceVariables} we arrive at the state-space model
We assume that only the position of the first object can be directly observed. This can be achieved using for example, infrared distance sensors. Under this assumption, the output equation has the following form The next step is to transform the state-space model \eqref{state:Mass_spring}-\eqref{output:Mass_spring} in the discrete-time domain. Due to its simplicity and good stability properties we use the Backward Euler method to perform the discretization. This method approximates the state derivative as follows where $h$ is the discretization time step. From the last equation, we have where and . On the othe hand, the output equation remains unchanged
In the sequel, we present a Python code for discretizing the system and for computing the system response to the control input signals. This code will be used to generate identification and validation data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
import numpy as np
import matplotlib.pyplot as plt
from numpy.linalg import inv
# define the system parameters
m1=20 ; m2=20 ; k1=1000 ; k2=2000 ; d1=1 ; d2=5;
# define the continuous-time system matrices
Ac=np.matrix([[0, 1, 0, 0],[-(k1+k2)/m1 , -(d1+d2)/m1 , k2/m1 , d2/m1 ], [0 , 0 , 0 , 1], [k2/m2, d2/m2, -k2/m2, -d2/m2]])
Bc=np.matrix([[0],[0],[0],[1/m2]])
Cc=np.matrix([[1, 0, 0, 0]])
#define an initial state for simulation
#x0=np.random.rand(2,1)
x0=np.zeros(shape=(4,1))
#define the number of time-samples used for the simulation and the sampling time for the discretization
time=300
sampling=0.05
#define an input sequence for the simulation
#input_seq=np.random.rand(time,1)
input_seq=5*np.ones(time)
#plt.plot(input_sequence)
I=np.identity(Ac.shape[0]) # this is an identity matrix
A=inv(I-sampling*Ac)
B=A*sampling*Bc
C=Cc
# check the eigenvalues
eigen_A=np.linalg.eig(Ac)[0]
eigen_Aid=np.linalg.eig(A)[0]
# the following function simulates the state-space model using the backward Euler method
# the input parameters are:
# -- Ad,Bd,Cd - discrete-time system matrices
# -- initial_state - the initial state of the system
# -- time_steps - the total number of simulation time steps
# this function returns the state sequence and the output sequence
# they are stored in the matrices Xd and Yd respectively
def simulate(Ad,Bd,Cd,initial_state,input_sequence, time_steps):
Xd=np.zeros(shape=(A.shape[0],time_steps+1))
Yd=np.zeros(shape=(C.shape[0],time_steps+1))
for i in range(0,time_steps):
if i==0:
Xd[:,[i]]=initial_state
Yd[:,[i]]=C*initial_state
x=Ad*initial_state+Bd*input_sequence[i]
else:
Xd[:,[i]]=x
Yd[:,[i]]=C*x
x=Ad*x+Bd*input_sequence[i]
Xd[:,[-1]]=x
Yd[:,[-1]]=C*x
return Xd, Yd
state,output=simulate(A,B,C,x0,input_seq, time)
plt.plot(output[0,:])
plt.xlabel('Discrete time instant-k')
plt.ylabel('Position- d')
plt.title('System response')
plt.savefig('step_response1.png')
plt.show()
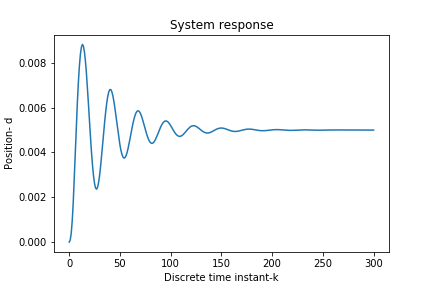
A few comments are in order. We generate a step control signal. The step response of the system is shown in the figure below. From the step response, we can see that the system is lightly damped.
 |
|---|
| Figure 2: System step response. |
Step-by-step Explanation of the Subspace Identification Algorithm
To simplify the derivations and for brevity, we first introduce the following notation.
Let be an arbitrary -dimensional vector, where denotes the discrete-time instant. The notation $\mathbf{d}_{i,j}$ denotes a -dimensional vector defined as follows
That is, the vector is formed by stacking the vectors on top of each other for an increasing time instant. This procedure is known as the lifting procedure. Using a similar procedure, we define a data matrix as follows
That is, the matrix is formed by stacking the vectors and by shifting the time index . Next, we need to define the operator that extracts rows or columns of a matrix. Let be an arbitrary matrix. The notation denotes a new matrix that is created from the rows of the matrix (without row permutations). Similarly, the notation stands for a matrix constructed from the corresponding columns of the matrix . This notation is inspired by the standard MATLAB notation which is also used in the Python programming language.
Step 1: Estimation of the VARX model or the System Markov Parameters
By substituting \eqref{eq1:outputDiscreteKalman} in \eqref{eq1:stateDiscreteKalman} and introducing a new notation, we obtain the following equation
where
For the development of the SI algorithm, it is important to introduce a parameter which is referred to as the past window. Starting from the time instant , and performing recursive substitutions of the equation\eqref{equation1}, we obtain
Following this procedure, we obtain
By multiplying \eqref{generatlizedControllability} from left by and by using the output equation \eqref{eq1:outputDiscreteKalman}, we can obtain where
The matrix is the matrix of Markov parameters. Due to the fact that the matrix is stable (even if the matrix is unstable, under some some relatively mild assumptions we can determine the matrix such that the matrix is stable), we have
for sufficiently large . By substituting \eqref{assumptionStability} in \eqref{outputEquation}, we obtain
This equation is actually an equation of a Vector AutoRegressive with eXogenous (VARX) inputs model. Namely, the system output at the time instant depends on the past inputs and outputs contained in the vector . The first step in the SI algorithm is to estimate the Markov parameters of the VARX model. That is, to estimate the matrix $\mathcal{M}_{p-1}$. This can be achieved by solving a least-squares problem. Namely, from \eqref{VARXequation}, we can write:
On the basis of the last equation, we can form the least-squares problem
where is the Frobenius matrix norm. The solution is given by
Next, we present the Python code to estimate the Markov parameters.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
###############################################################################
# This function estimates the Markov parameters of the state-space model:
# x_{k+1} = A x_{k} + B u_{k} + Ke(k)
# y_{k} = C x_{k} + e(k)
# The function returns the matrix of the Markov parameters of the model
# Input parameters:
# "U" - is the input vector of the form U \in mathbb{R}^{m \times timeSteps}
# "Y" - is the output vector of the form Y \in mathbb{R}^{r \times timeSteps}
# "past" is the past horizon
# Output parameters:
# The problem beeing solved is
# min_{M_pm1} || Y_p_p_l - M_pm1 Z_0_pm1_l ||_{F}^{2}
# " M_pm1" - matrix of the Markov parameters
# "Z_0_pm1_l" - data matrix used to estimate the Markov parameters,
# this is an input parameter for the "estimateModel()" function
# "Y_p_p_l" is the right-hand side
def estimateMarkovParameters(U,Y,past):
import numpy as np
import scipy
from scipy import linalg
timeSteps=U.shape[1]
m=U.shape[0]
r=Y.shape[0]
l=timeSteps-past-1
# data matrices for estimating the Markov parameters
Y_p_p_l=np.zeros(shape=(r,l+1))
Z_0_pm1_l=np.zeros(shape=((m+r)*past,l+1)) # - returned
# the estimated matrix that is returned as the output of the function
M_pm1=np.zeros(shape=(r,(r+m)*past)) # -returned
# form the matrices "Y_p_p_l" and "Z_0_pm1_l"
# iterate through columns
for j in range(l+1):
# iterate through rows
for i in range(past):
Z_0_pm1_l[i*(m+r):i*(m+r)+m,j]=U[:,i+j]
Z_0_pm1_l[i*(m+r)+m:i*(m+r)+m+r,j]=Y[:,i+j]
Y_p_p_l[:,j]=Y[:,j+past]
# numpy.linalg.lstsq
#M_pm1=scipy.linalg.lstsq(Z_0_pm1_l.T,Y_p_p_l.T)
M_pm1=np.matmul(Y_p_p_l,linalg.pinv(Z_0_pm1_l))
return M_pm1, Z_0_pm1_l, Y_p_p_l
###############################################################################
# end of function
###############################################################################
To estimate the Markov parameters, we need to slect the past window . The problem of optimal selection of the past window is an important problem, and we will deal with this problem in our next post
Step 2: Estimation of the State-Sequence
Once the Markov parameters are estimated, we can proceed with the estimation of the state sequence. The main idea is that if we would know the state sequence , then we would be able to estimate the system matrices and of the state-space model \eqref{eq1:stateDiscreteKalman}-\eqref{eq1:outputDiscreteKalman} using a simple least-squares method.
From \eqref{generatlizedControllability} and the assumption \eqref{assumptionStability}, we have
Besides the past window , another user-selected parameter is defined in the SI algorithm. This parameter is called the future window and is denoted by . The future window needs to satisfy the following condition . For a selected future window , we define the following matrix
By multiplying the equation \eqref{stateExpressed} with , we obtain
Taking the assumption \eqref{assumptionStability} into account, from \eqref{stateExpressed2}, we have
Now, let us analyze the matrix in \eqref{stateExpressed3}. Its first block row is the matrix . Its second block row is the matrix composed of a block zero matrix and the matrix in which the last block has been erased, etc. That is, the matrix can be completely reconstructed using the Markov parameter matrix. Let denote the matrix constructed on the basis of the estimated matrix . This matrix is formally defined as follows:
On the basis of the equations \eqref{stateExpressed3} and \eqref{hatMatrixQ}, and by iterating the index from to , we obtain
Now, let us analyze the equation \eqref{equation4expressed}. We are interested to obtain the estimate of the matrix . That is, to obtain the estimate of the state-sequence, such that we can in the later stage estimate the system matrices. The left-hand side of the equation is completely unknown and the right-hand side is known since we have estimated the matrix . If we would know the matrix , then we would be able to solve this equation for . However, we do not know this matrix and it seems that our efforts to estimate the model are doomed to fail.
Now, here comes the magic of numerical linear algebra! Under some assumptions, from the equation \eqref{equation4expressed} it follows that we can obtain the estimate of the matrix by computing the row space of the matrix . The row space can be computed by computing the singular value decomposition:
where $U,V$ are orthonormal matrices, and the matrix is the matrix of singular values. Let , denote the estimate of the state-order (we will explain in the sequel a simple method to estimate the state order and a more complex method will be explained in our next post). Then, the estimate of the matrix , denoted by is computed as follows where . Once we have estimated the matrix we can obtain the estimate of the state sequence because:
Step 3: Estimation of the System Matrices
Now that we have estimated the state sequence, we can estimate the system matrices by forming two least squares problems. Namely, from \eqref{equation1}, we have
Since the matrix is known, the matrix can be estimated by solving
The solution is given by
Similarly, from the output equation \eqref{eq1:outputDiscreteKalman}, we have: and the matrix can be estimated by forming a similar least squares problem
The solution is given by
Once these matrices have been estimated, we can obtain the system matrices as follows:
where the etimates of the matrices , and are denoted by , and , respectively.
The Python code for estimating the matrices is given below.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
###############################################################################
# This function estimates the state-space model:
# x_{k+1} = A x_{k} + B u_{k} + Ke(k)
# y_{k} = C x_{k} + e(k)
# Acl= A - KC
# Input parameters:
# "U" - is the input matrix of the form U \in mathbb{R}^{m \times timeSteps}
# "Y" - is the output matrix of the form Y \in mathbb{R}^{r \times timeSteps}
# "Markov" - matrix of the Markov parameters returned by the function "estimateMarkovParameters()"
# "Z_0_pm1_l" - data matrix returned by the function "estimateMarkovParameters()"
# "past" is the past horizon
# "future" is the future horizon
# Condition: "future" <= "past"
# "order_estimate" - state order estimate
# Output parameters:
# the matrices: A,Acl,B,K,C
# s_singular - singular values of the matrix used to estimate the state-sequence
# X_p_p_l - estimated state sequence
def estimateModel(U,Y,Markov,Z_0_pm1_l,past,future,order_estimate):
import numpy as np
from scipy import linalg
timeSteps=U.shape[1]
m=U.shape[0]
r=Y.shape[0]
l=timeSteps-past-1
n=order_estimate
Qpm1=np.zeros(shape=(future*r,past*(m+r)))
for i in range(future):
Qpm1[i*r:(i+1)*r,i*(m+r):]=Markov[:,:(m+r)*(past-i)]
# estimate the state sequence
Qpm1_times_Z_0_pm1_l=np.matmul(Qpm1,Z_0_pm1_l)
Usvd, s_singular, Vsvd_transpose = np.linalg.svd(Qpm1_times_Z_0_pm1_l, full_matrices=True)
# estimated state sequence
X_p_p_l=np.matmul(np.diag(np.sqrt(s_singular[:n])),Vsvd_transpose[:n,:])
X_pp1_pp1_lm1=X_p_p_l[:,1:]
X_p_p_lm1=X_p_p_l[:,:-1]
# form the matrices Z_p_p_lm1 and Y_p_p_l
Z_p_p_lm1=np.zeros(shape=(m+r,l))
Z_p_p_lm1[0:m,0:l]=U[:,past:past+l]
Z_p_p_lm1[m:m+r,0:l]=Y[:,past:past+l]
Y_p_p_l=np.zeros(shape=(r,l+1))
Y_p_p_l=Y[:,past:]
S=np.concatenate((X_p_p_lm1,Z_p_p_lm1),axis=0)
ABK=np.matmul(X_pp1_pp1_lm1,np.linalg.pinv(S))
C=np.matmul(Y_p_p_l,np.linalg.pinv(X_p_p_l))
Acl=ABK[0:n,0:n]
B=ABK[0:n,n:n+m]
K=ABK[0:n,n+m:n+m+r]
A=Acl+np.matmul(K,C)
return A,Acl,B,K,C,s_singular,X_p_p_l
###############################################################################
# end of function
###############################################################################
Model estimation in practice
To identify the model and to test the model performance, we need to generate two sets of data. The first set of data, referred to as the identification data set is used to identify the model. This data set is generated for a random initial condition and for a random input sequence. Not every input sequence can be used for system identification. The input sequence needs to satisfy the so called persistency of excitation condition. Roughly speaking, the identification sequence needs to be rich enough to excite all the system modes. Usually, a random sequence will satisfy this condition. Besides, the identification data set, we are using another data set. This data set, that is referred to as the validation data set is used to test the estimated model performance. This data set is generated for a random initial condition and for a random input sequence. The validation initial state and the input sequence are generated such that they are statistically independent from the initial state and the input sequence used for the identification.
All the functions used for the identification are stored in the file “functionsSID”. Here we provide a detailed explanation of the driver code. As a numerical example, we use the example introduce at the beginning of this post. We start with the explanation of the code. The following code is used to import the necessary functions and to define the model.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
import numpy as np
import matplotlib.pyplot as plt
from numpy.linalg import inv
from functionsSID import estimateMarkovParameters
from functionsSID import estimateModel
from functionsSID import systemSimulate
from functionsSID import estimateInitial
from functionsSID import modelError
###############################################################################
# Define the model
# masses, spring and damper constants
m1=20 ; m2=20 ; k1=1000 ; k2=2000 ; d1=1 ; d2=5;
# define the continuous-time system matrices
Ac=np.matrix([[0, 1, 0, 0],[-(k1+k2)/m1 , -(d1+d2)/m1 , k2/m1 , d2/m1 ], [0 , 0 , 0 , 1], [k2/m2, d2/m2, -k2/m2, -d2/m2]])
Bc=np.matrix([[0],[0],[0],[1/m2]])
Cc=np.matrix([[1, 0, 0, 0]])
# end of model definition
###############################################################################
###############################################################################
The following code lines are used to define the identification parameters and to define the identification and validation data sets.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
###############################################################################
# parameter definition
r=1; m=1 # number of inputs and outputs
# total number of time samples
time=300
# discretization constant
sampling=0.05
# model discretization
I=np.identity(Ac.shape[0]) # this is an identity matrix
A=inv(I-sampling*Ac)
B=A*sampling*Bc
C=Cc
# check the eigenvalues
eigen_A=np.linalg.eig(Ac)[0]
eigen_Aid=np.linalg.eig(A)[0]
# define an input sequence and initial state for the identification
input_ident=np.random.rand(1,time)
x0_ident=np.random.rand(4,1)
#define an input sequence and initial state for the validation
input_val=np.random.rand(1,time)
x0_val=np.random.rand(4,1)
# simulate the discrete-time system to obtain the input-output data for identification and validation
Y_ident, X_ident=systemSimulate(A,B,C,input_ident,x0_ident)
Y_val, X_val=systemSimulate(A,B,C,input_val,x0_val)
# end of parameter definition
###############################################################################
A few comments are in order. The code lines 11-14 are used to discretize the model. The code lines 17-18 are used to check the eigenvalues of the models. This is important for detecting possible instabilities. The code lines 21-30 are used to define the identification and validation data sets.
The following code is used to estimate the model and to perform the model validation.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
###############################################################################
# model estimation and validation
# estimate the Markov parameters
past_value=10 # this is the past window - p
Markov,Z, Y_p_p_l =estimateMarkovParameters(input_ident,Y_ident,past_value)
# estimate the system matrices
model_order=3 # this is the model order \hat{n}
Aid,Atilde,Bid,Kid,Cid,s_singular,X_p_p_l = estimateModel(input_ident,Y_ident,Markov,Z,past_value,past_value,model_order)
plt.plot(s_singular, 'x',markersize=8)
plt.xlabel('Singular value index')
plt.ylabel('Singular value magnitude')
plt.yscale('log')
#plt.savefig('singular_values.png')
plt.show()
# estimate the initial state of the validation data
h=10 # window for estimating the initial state
x0est=estimateInitial(Aid,Bid,Cid,input_val,Y_val,h)
# simulate the open loop model
Y_val_prediction,X_val_prediction = systemSimulate(Aid,Bid,Cid,input_val,x0est)
# compute the errors
relative_error_percentage, vaf_error_percentage, Akaike_error = modelError(Y_val,Y_val_prediction,r,m,30)
print('Final model relative error %f and VAF value %f' %(relative_error_percentage, vaf_error_percentage))
# plot the prediction and the real output
plt.plot(Y_val[0,:100],'k',label='Real output')
plt.plot(Y_val_prediction[0,:100],'r',label='Prediction')
plt.legend()
plt.xlabel('Time steps')
plt.ylabel('Predicted and real outputs')
#plt.savefig('results3.png')
plt.show()
# end of code
###############################################################################
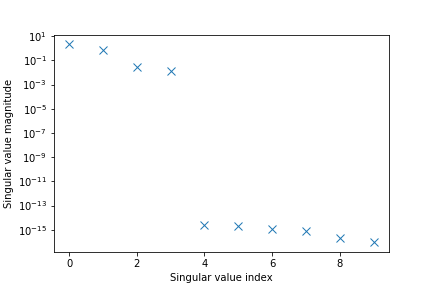
The code lines 5-6 are used to estimate the Markov parameters. We guess the value of the past window (a systematic procedure for selecting the past window will be explained in the next post). The code lines 9-10 are used to estimate the model. Here we also guess the model order. However, there is a relatively simple method to visually select a model order (a more advanced model order selection method will be explained in the next post). Namely, the function estimateModel() also returns the singular values of the matrix , see the equation \eqref{SVDmatrix}. We can select the model order on the basis of the gap between the singular values. Figure 3 below shows the magnitudes of the singular values.
 |
|---|
| Figure 3: Singular values used to estimate the model order . |
In Fig. 3. we can clearly detect a gap between the singular value 4 and 5. This means that 4 is a good estimate of the model order. In fact, this is the exact model order, since our system is of the fourth order. This graph is generated using the code lines 12-17.
The code lines 19-21 are used to estimate the initial state of the validation data. Namely, to test the model performance, we need to simulate the estimated model using the validation input sequence. However, to perform the simulation, we need to know the initial states. The identified model has been simulated using the code line 24. The code lines 27-28 are used to compute the relative model error (a relative error measured by the 2-norm between the true validation output and the predicted one). The code lines 31-37 are used to plot the predicted validation output and the true validation output. The results for several model orders are shown in Figure 4 below.
 |
|---|
| Figure 4: Outputs of the estimated model and the original one for the validation input sequence . |
An interesting phenomenon can be observed. Namely, the relative error for the model order of 2 is smaller than the relative error for the model order of 3.
We hope that we have convinced you of a superior performance of the subspace identification algorithms. Notice that we are able to estimate the model by performing only numerical linear algebra steps, without the need to use the complex optimization techniques!